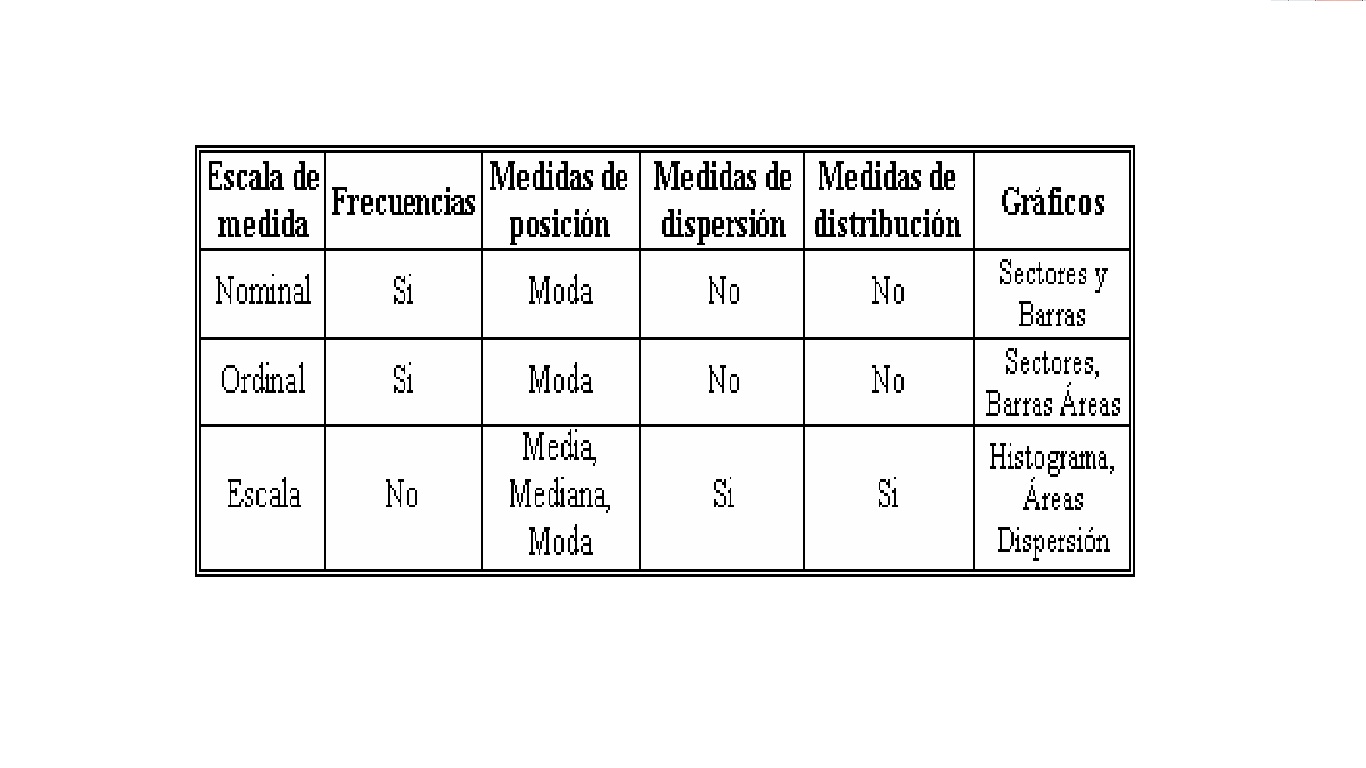
Para realizar un correcto análisis de los datos es fundamental conocer de antemano el tipo de medida de la variable, ya que para cada una de ellas se utilizan diferentes estadísticos. La clasificación más convencional de las escalas de medida se divide en cuatro grupos denominados Nominal, Ordinal, Intervalo y Razón.
Nominal
Son variables numéricas cuyos valores representan una categoría distintiva que no implican un orden específico o identifican un grupo de pertenencia Este tipo de variables sólo nos permite establecer relaciones de igualdad/desigualdad entre los elementos de la variable. La asignación de los valores se realiza en forma aleatoria por lo que NO cuenta con un orden lógico. Un ejemplo de este tipo de variables es el Género ya que nosotros podemos asignarles un valor a los (A) hombres y otro diferente a las mujeres (B) y por más machistas o feministas que seamos no podríamos establecer que uno es mayor que el otro. O Bien se clasificará a una muestra de personas de acuerdo a la religión que profesan: (1) Cristianos, (2) Judíos, (3) Musulmanes, (4) Otros y (5) Sin creencia alguna.

A B
Ordinal
Son variables numéricas cuyos valores representan una categoría o identifican un grupo de pertenencia contando con un orden lógico. Este tipo de variables
nos permite establecer relaciones de igualdad/desigualdad y a su vez, podemos identificar si una categoría es mayor o menor que otra. La medición ordinal permite ordenar los eventos en función de mayor o menor posesión de un atributo o característica. Un ejemplo de variable ordinal es el nivel de educación, ya que se puede establecer que una persona con título de Postgrado tiene un nivel de educación superior al de una persona con título de bachiller. En las variables ordinales no se puede determinar la distancia entre sus categorías, ya que no es cuantificable o medible.

Intervalo
Son variables numéricas cuyos valores representan magnitudes y la distancia entre los números de su escala es igual. Con este tipo de variables podemos realizar comparaciones de igualdad/desigualdad, establecer un orden dentro de sus valores y medir la distancia existente entre cada valor de la escala, sobre todo es aplicable a las variables continuas debido a que la multiplicación y la división no son realizables. Un ejemplo de este tipo de variables es la temperatura, ya que podemos decir que la distancia entre 10 y 12 grados es la misma que la existente entre 15 y 17 grados. Lo que no podemos establecer es que una temperatura de 10 grados equivale a la mitad de una temperatura de 20 grados.

Razón
Las variables de razón poseen las mismas características de las variables de intervalo, con la diferencia que cuentan con un cero absoluto; es decir, el valor cero (0) representa la ausencia total de medida, por lo que se puede realizar cualquier operación Aritmética (Suma, Resta, Multiplicación y División) y Lógica (Comparación y ordenamiento). Este tipo de variables permiten el nivel más alto de medición, además que determinan la distancia exacta entre los intervalos de una categoría Las variables altura, peso, distancia o el salario, son algunos ejemplos de este tipo de escala de medida. Debido a la similitud existente entre las escalas de intervalo y de razón, el Stadistic Program Social System (SPSS) las ha reunido en un nuevo tipo de medida exclusivo del programa, al cual denomina Escala. Las variables de escala son para SPSS todas aquellas variables cuyos valores representan magnitudes, ya sea que cuenten con un cero (0) absoluto o no. Teniendo esto en cuenta discutiremos a continuación los diferentes procedimientos estadísticos que se pueden utilizar de acuerdo al tipo de medida de cada variable.
Tabla de frecuencia para variables discretas y continuas